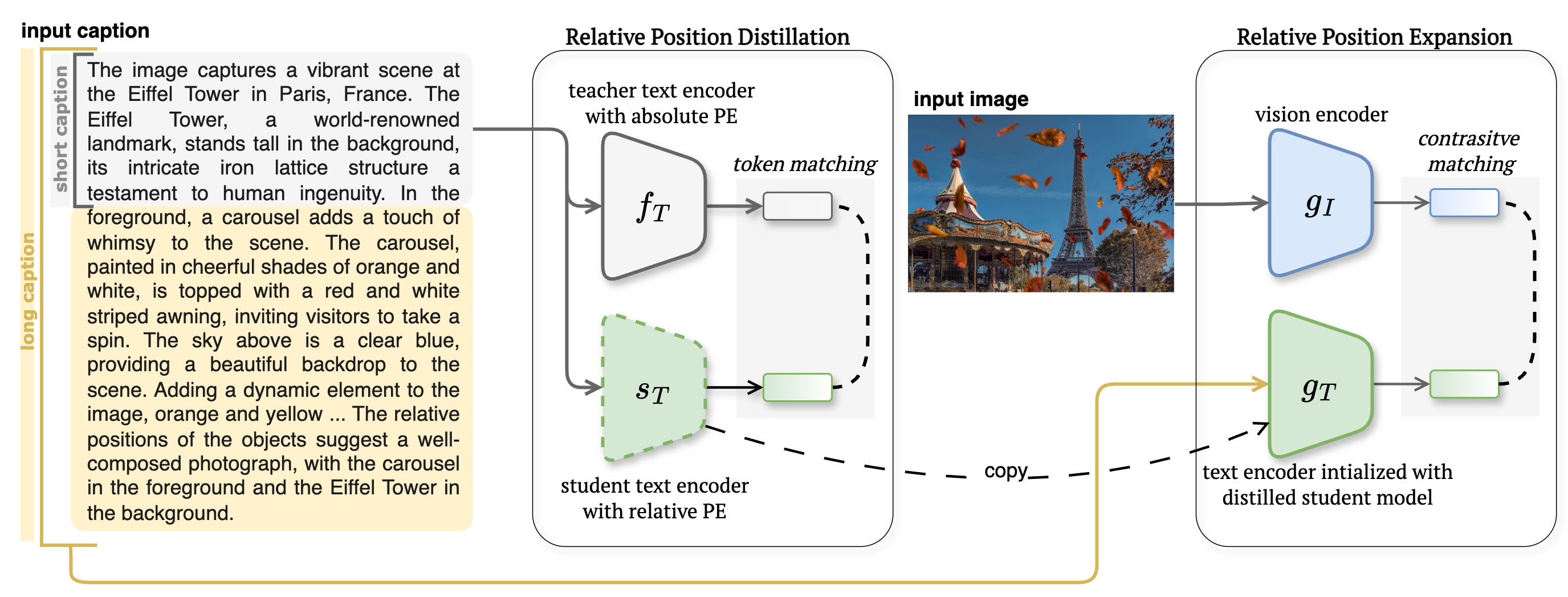
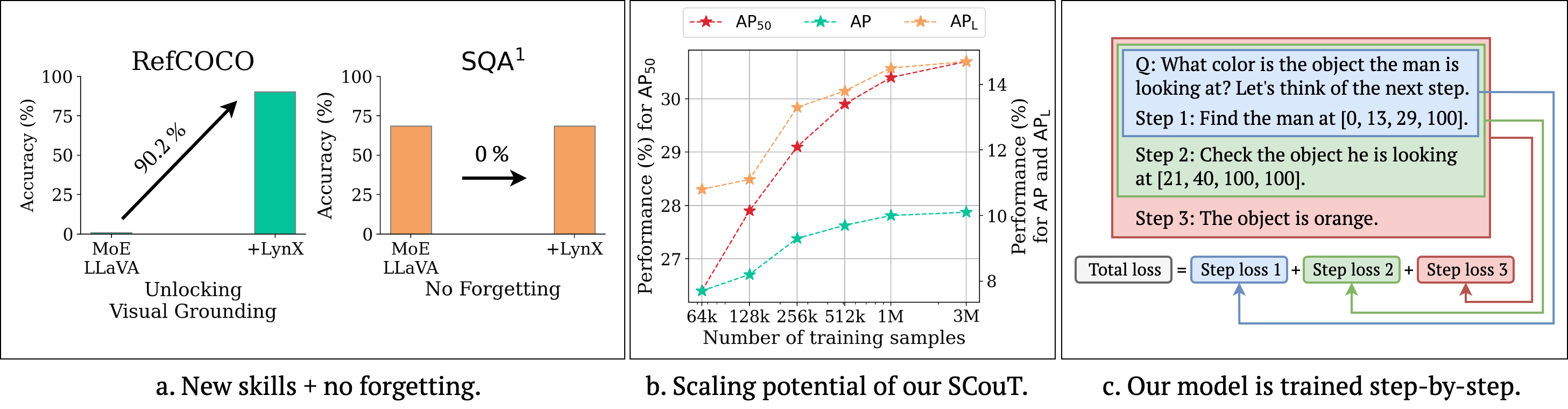
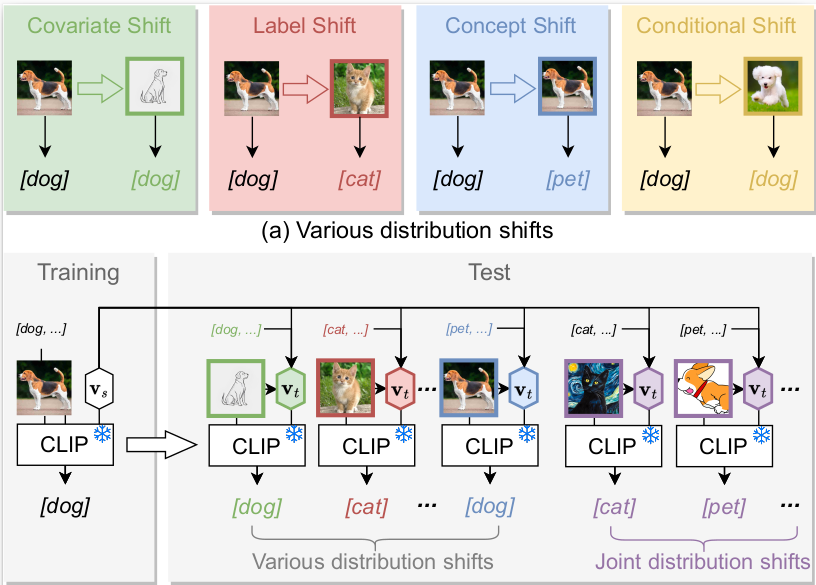
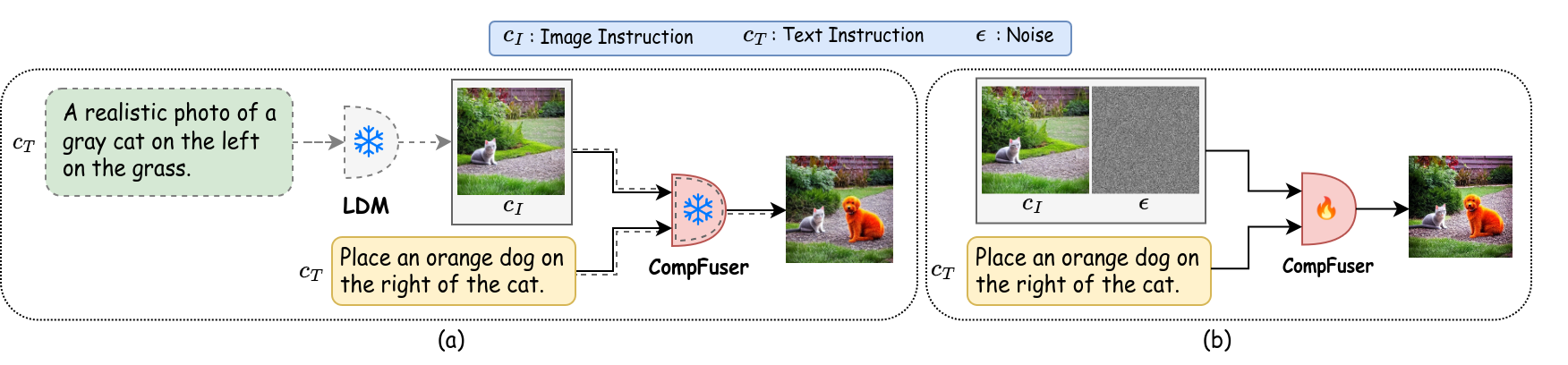
Mohammad Mahdi Derakhshani
Computer Vision | Machine Learning
Welcome! I'm Mohammad, a Ph.D. student at the University of Amsterdam's VIS lab under the supervision of Cees
Snoek and Yuki
Asano. My research delves into multi-modal foundation models, with a keen interest in unified generative models. I am currently a community researcher at Cohere Lab, focusing on multilingual generative models.
In summer 2023, I interned at Microsoft Research, Cambridge, working on fine-tuning large-scale LLMs, e.g.
GPT3 and GPT3.5 and conditional text-to-image generation
alongside Molly Xia,
Harkirat Behl and
Victor Ruehle.
In summer 2022, I was at Samsung AI Center, Cambridge, researching large-scale language-image models and
Federated Learning with Brais Martinez and
Georgios
Tzimiropoulos.
Before that, I pursued my master's at the University of Tehran under the guidance of Babak Nadjar Araabi and Mohammad Amin
Sadeghi. My studies at the Machine Learning and Computational Modeling lab focused on object
detection and image compression. I also researched object detection with Mohammad Rastegari.
I'm proud to be an ELLIS society
member and have reviewed for prestigious conferences such as CVPR, NeurIPs, ICLR, ICML, ICCV and TPAMI.